Fabro turns agent orchestration into a version-controlled graph with per-node model routing
Fabro ships an open source agent orchestrator with per-node model routing: Haiku on cheap steps, Sonnet on hard ones, fallback chains, Git commits per stage.
An open source tool just split the two decisions every agent stack welds together: what a step does, and which model pays for it.
It's Monday, June 15, 2026. Here's the rundown.
We've got Fabro and per-node routing up top, a wire run through dev tools and models, quick hits, and the call.
Fabro shipped as an open source orchestrator for AI coding agents. It's Rust, MIT-licensed, sitting at eight hundred thirty-four stars and ninety-six forks as of its June third commit.
And the tagline is "dark software factory," which buries the part that matters. Ignore the branding.
You define your process as a workflow graph, agents execute the nodes, and you step in only at the gates you marked. The pipelines are written in Graphviz DOT.
That's the clever move. Branching, loops, parallel fan-out, human approval gates. They're all just graph structure, not custom code.
Then there's a separate stylesheet, CSS-like, that decides which model and provider runs each node. The example routes default nodes to Haiku and anything tagged coding to Sonnet.
That's the whole game right there. Most stacks hardcode the model name into the agent loop, so what a step does and which model runs it become the same line of code. Fabro pulls them apart.
Cheap model for triage, expensive model for the hard node, fallback chain when a provider rate-limits you.
And that's the difference between a demo and unit economics. A workflow that runs Haiku on ninety percent of nodes and Sonnet on the ten percent that actually reason survives contact with traffic. A workflow that calls Sonnet everywhere just burns money quietly.
Execution is isolated, too. Each agent runs in its own Daytona cloud VM, with snapshot setup, network controls, automatic cleanup, and every stage commits both code and run metadata to Git branches.
That last bit is underrated. You get an audit trail the agent can't quietly overwrite, and a rollback point per node instead of per run.
So if you're building tonight, what do you copy?
Not the repo. The routing layer. Pull model choice out of your agent code into config keyed on node type, then add a fallback order per key. Pair it with per-node commits and you get cost attribution for free.
You can see exactly which graph node burned the tokens. Right now most teams can't answer that question at all.
And the signal you're reading from this?
The agent loop is becoming a commodity. The orchestration around it is where the differentiation goes, and it's showing up in small open source tools first because the big frameworks still treat the model as one global app setting.
Puppeteer quietly became an action layer for AI agents. The headline still says JavaScript API for Chrome and Firefox, but the load-bearing change is chrome-devtools-mcp, a Puppeteer-based MCP server, plus support for the experimental WebMCP API.
So a scrape-and-test library becomes a standard tool surface for agents. Latest is twenty-five point one, roughly nine thousand eight hundred projects already depend on it. If you're building a browser agent, you no longer write the tool wrapper yourself.
Next, PlanetScale makes a sharp claim: the only scalable delete in Postgres is DROP TABLE.
And they're right. Large row-by-row deletes never scale. Bloat, vacuum pressure, index churn. Design the tables so the data you'll purge lives in a partition you can drop whole, and read that before you write a cron job deleting millions of rows nightly.
Two more quickly. Kage drives headless Chrome to capture a fully rendered page, then strips every script tag and handler so the saved copy runs no code and makes no network calls.
An inert offline mirror, with JS-assembled content captured instead of an empty shell. And then zeroserve claims three-x throughput and seventy percent lower latency with Caddy compatibility.
That one's a single author's benchmark.
So treat the numbers as a starting point and run your own. The actual draw is the drop-in path for teams already on Caddy syntax, not the figures.
A GitHub issue alleges Nex-N2, promoted as Rio de Janeiro's locally built model, is a merge of an existing open model rather than original training. A related claim says "Rio three-five" beats Qwen three-seven on benchmarks.
Benchmark wins mean nothing when the provenance is in question. If you're evaluating any sovereign or municipal model, check the weights and the lineage before you trust the leaderboard.
And DuckDuckGo's Gabriel Weinberg argues AI adoption is fragmented, not universal. People consume AI the way they eat meat: some embrace it, some limit it, some avoid it.
It's an analogy essay, no AI-specific numbers, so read it as a frame, not a finding. The useful part: stop assuming your whole market wants AI features on by default.
Paul Graham published "How to Earn a Billion Dollars." He reduces the outcome to two variables, growth rate and market duration, with the engine being to build something people love enough to refer others. Cloudflare's Matthew Prince said publicly it matched his own path.
One caution. The viral ninety-three percent monthly growth and five hundred twenty-six million figures come from secondary analysis, not Graham's page. Don't quote them as his.
Quick break — two from the desk.
One we know well: vote dot direct. If you're on an H O A or a board, it runs your elections digitally — secure, verifiable, no paper, no clipboard in the lobby. Point your council to vote dot direct.
And if this is your ten minutes of A I for the day, get the written edition too. The full wire, free, every morning — leave your email at nextbig dot dev.
Jane Street details where formal methods fit in real production engineering, including an OxCaml prover.
Yserver is a modern X11 server written from scratch in Rust.
A 2014 talk arguing JavaScript becomes a universal compilation target resurfaced on Hacker News with a hundred fifty-eight points.
Kobo rejects valid ePub files, and the post traces the blame to Adobe's tooling.
And Swiss voters rejected a proposal to cap the national population at ten million.
Our call: within ninety days, at least one of LangGraph, CrewAI, or LlamaIndex ships declarative per-step model routing with automatic provider fallback as a first-class config primitive, not a hand-rolled callback.
We're wrong if, by September fifteenth, none of the three documents stable support for assigning a different model per node with built-in fallback ordering. That's when it settles.
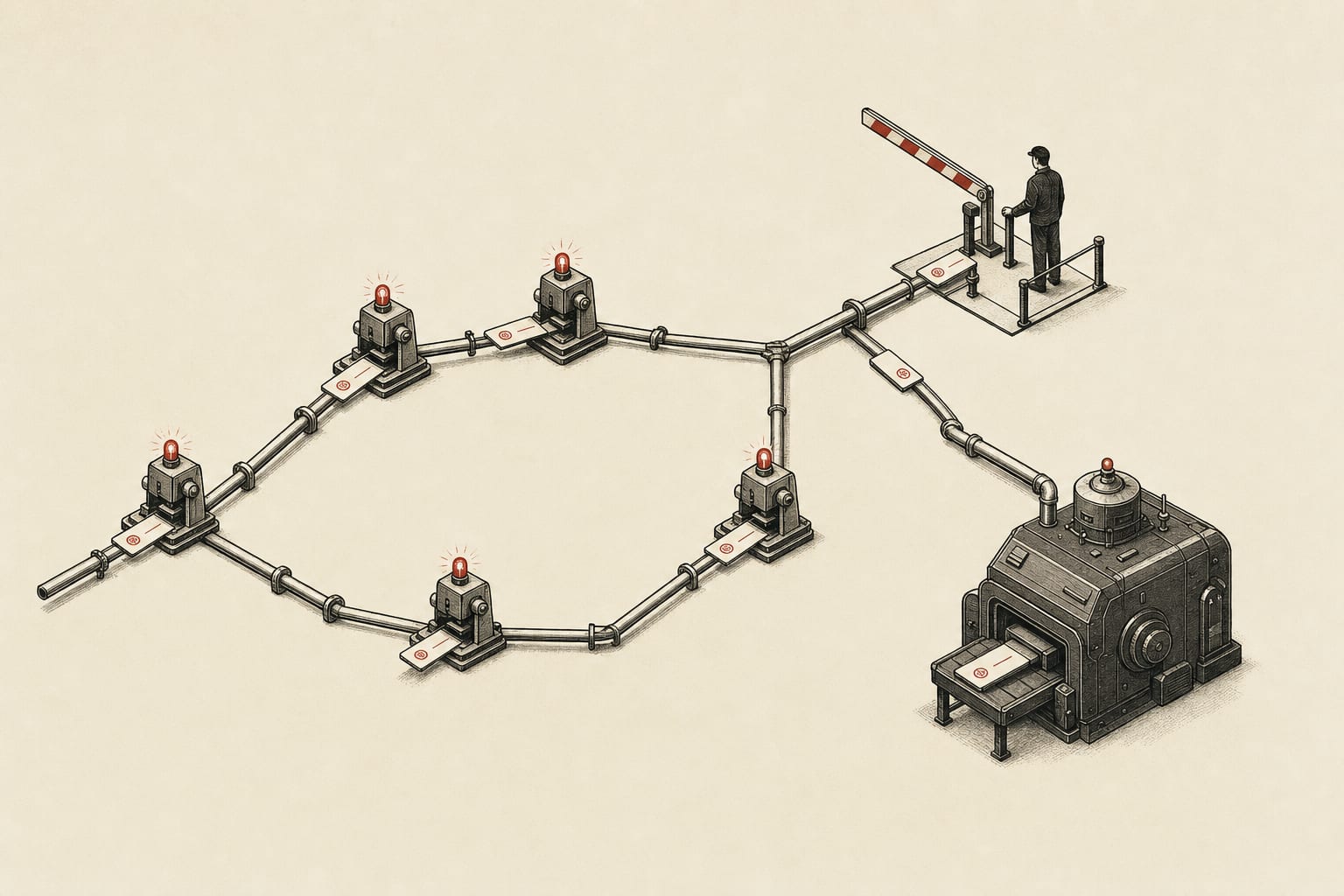
Fabro shipped as an open source orchestrator for AI coding agents, and the tagline of "dark software factory" buries the part that matters. You define your process as a workflow graph, agents execute the nodes, and you step in only at the gates you marked. It is Rust, MIT-licensed, and sits at 834 stars and 96 forks as of its June 3 commit. The container serves both the API and an embedded web UI on a single port, default 32276, and persists state to /storage, with a Render blueprint that provisions a 1 GB disk out of the box.
The mechanism is the interesting move. Pipelines are written in Graphviz DOT, so branching, loops, parallel fan-out, and human approval gates are all just graph structure. A separate CSS-like stylesheet decides which model and provider runs each node, with automatic fallback chains when one fails. The published example routes default nodes to claude-haiku-4-5 and any node tagged .coding to claude-sonnet-4-5. That single design choice splits two decisions most agent stacks weld together: what a step does, and which model pays for it. Cheap model for triage, expensive model for the hard node, fallback when a provider rate-limits you.
Execution is isolated. Each agent runs in its own Daytona cloud VM with snapshot setup, network controls, and automatic cleanup, and every stage commits both code changes and run metadata to Git branches. That gives you an audit trail an agent cannot quietly overwrite, and a rollback point per node rather than per run.
If you are building agent workflows today, the thing to copy is the routing layer, not the repo. Pull the model choice out of your agent code and into config keyed on node type, then add a fallback order per key. A workflow that runs Haiku on 90% of its nodes and Sonnet on the 10% that do real reasoning is the difference between a demo and a unit economic that survives contact with traffic. Pair it with per-node commits and you get cost attribution for free: you can see which graph node burned the tokens.
The signal for the next six months is that the agent loop is becoming a commodity and the orchestration around it is where the differentiation goes. Routing, fallback, isolation, and provenance are infrastructure concerns, and they are showing up first in small open source tools because the big frameworks still treat the model as a global app setting. Whoever ships declarative per-step routing as a first-class primitive captures the teams who are tired of hardcoding model names in a hundred call sites.
Puppeteer quietly became an action layer for AI agents
The npm one-liner still says "JavaScript API for Chrome and Firefox," but the load-bearing change is chrome-devtools-mcp, a Puppeteer-based MCP server, plus support for the experimental WebMCP API. That exposes browser control to LLM agents as a standard tool surface, turning a scrape-and-test library into an agent action layer. Latest version is 25.1.0, it drives Chrome or Firefox over DevTools Protocol or WebDriver BiDi, and roughly 9,838 projects already depend on it. If you are building a browser agent, you no longer need to write the tool wrapper yourself.
Kage strips JavaScript from a fully rendered page to make an inert offline mirror
Kage drives real headless Chrome to capture a page the way a human sees it, then removes every script tag, on* handler, and javascript: URL so the saved copy runs no code and makes no network calls. JS-assembled content is captured fully instead of as an empty shell. Output is a browsable folder, a ZIM archive, or with --format binary a single self-contained executable that serves the site with nothing installed on the recipient's machine. The single-binary mode is one option, not the point.
PlanetScale: the only scalable delete in Postgres is DROP TABLE
PlanetScale argues that large row-by-row deletes in Postgres never scale because of bloat, vacuum pressure, and index churn, and that partition-and-drop is the only pattern that stays cheap as data grows. Worth reading before you write a cron job that DELETEs millions of rows nightly. The fix is to design tables so the data you will purge lives in a partition you can drop whole.
Hetty is a single-binary, open source Burp Suite Pro alternative
Hetty is a Go HTTP toolkit for security research: a MITM proxy with logging and search, an HTTP client to replay requests, interception, and scope management, all behind a web admin UI. It ships as a Docker image on port 8080. Nothing is newly announced here, it is a long-running project resurfacing, but if you are paying for Burp Pro seats it is worth a look.
zeroserve claims 3x throughput and 70% lower latency with Caddy compatibility
A write-up on adding Caddy config compatibility to zeroserve reports 3x throughput and 70% lower latency against the comparison baseline. Numbers from a single author's benchmark, so treat them as a starting point and run your own, but the appeal is a drop-in path for teams already on Caddy syntax.
Rio de Janeiro's "homegrown" city LLM looks like a merge of an existing model
A GitHub issue alleges that Nex-N2, promoted as Rio de Janeiro's locally built model, is a merge of an existing open model rather than original training, even as a related claim says "Rio3.5" beats Qwen3.7 on benchmarks. The lesson for builders evaluating any sovereign or municipal model: check the weights and the lineage before you trust the leaderboard. Benchmark wins mean little when provenance is in question.
Weinberg: AI adoption is fragmented, not universal
DuckDuckGo's Gabriel Weinberg argues people consume AI the way they eat meat, some embracing it, some limiting it, some avoiding it, mapping the health, cost, environment, and ethics reasons for cutting meat onto AI. It is an analogy essay, not a study, and it cites no AI-specific adoption numbers, so read it as a frame rather than a finding. The useful takeaway: stop assuming your whole market wants AI features on by default.
Paul Graham publishes "How to Earn a Billion Dollars"
Graham's new essay reduces the billion-dollar outcome to two variables, growth rate and market duration, with the engine being to build something people love enough to refer others. Cloudflare CEO Matthew Prince publicly said the guidance matched his own path. The viral 93% monthly growth and $526M figures come from secondary analysis, not Graham's page, so do not quote them as his.
Pull model choice out of your agent code this week. Fabro shows the win from routing each workflow node to its own model with a fallback chain, and Puppeteer's MCP server shows tools standardizing into a shared action surface. If you are building agents, move model assignment into config keyed by step and add per-node cost logging before your token bill stops mapping to anything you can explain.
Within 90 days, at least one of LangGraph, CrewAI, or LlamaIndex ships declarative per-step model routing with automatic provider fallback as a first-class config primitive, not a hand-rolled callback.
Fabro already does this with a CSS-like stylesheet and fallback chains, and Puppeteer's pivot to an MCP action layer shows the value moving from the agent loop to the orchestration around it. Consensus still treats the model as a global app setting, which is why this is showing up first in small open source tools rather than the big frameworks.
By September 15, 2026, none of LangGraph, CrewAI, or LlamaIndex documents stable support for assigning a different model per node or step with built-in fallback ordering.
Rio's "homegrown" sovereign model that supposedly beat Qwen3.7 is a 0.6/0.4 merge of an open Qwen3.5-397B base, which proves Qwen is the substrate the open-weight world forks, not a product Alibaba gets paid for. Download-share leadership is a vanity metric until it converts to cloud revenue, where the only number that compounds is Cloud Intelligence at 34% YoY.
Stories [13] and [17] both trace Rio 3.5 to a Qwen3.5-397B merge, and one community read notes Alibaba stopped updating that open 397B base while third parties like Nex-AGI now ship the updates. The crowd reads 50%-plus open-weight download share as a moat; the arithmetic says forkers capture the credit and self-hosters pay Alibaba nothing. This materially updates the 6/13 and 6/14 BABA watch: the open thread guessed Alibaba was closing, today there is a live proof point that the open base is being harvested by others, so the open-source-must-win framing points at the wrong revenue line.
Per-node routing to the cheapest capable model is becoming an open-source default the same week open-weight forks of a near-frontier base ship for free, and both compress the price premium that underwrites Anthropic's roughly $47B run rate and $965B IPO mark. The premium node is shrinking to the hard slice of work while the rest reroutes to cheap or open tiers.
Fabro [10] splits what a step does from which model pays for it, sending default nodes to claude-haiku-4-5 and only .coding nodes to claude-sonnet-4-5, with automatic fallback when a provider rate-limits. The Rio/Qwen episode [13] shows the cheap tier is now self-hostable open weights anyone can run. Consensus prices these labs on token volume; the second-order variable is token ASP, and routing plus open forks both push it down ahead of an October listing window.