Claude burned through 2h37m of degraded models in a single day, and it is the third straight week
Claude logged 2h37m of degraded models in one day, the third straight week of capacity-bound outages. What it means for any team running Claude Code in CI.
Claude went dark for two hours and thirty-seven minutes yesterday, and that's the third week running it's failed at the exact hour US teams ship.
It's Wednesday, June 24, 2026. Here's the rundown. We've got a provider rationing capacity, China taking the Top500 on CPUs alone, and a 744-billion model running on a Mac.
Anthropic logged elevated error rates starting just after two in the afternoon UTC on Monday. By the close of the day Claude had been degraded two hours and thirty-seven minutes, across the website, the API, the Console, Claude Code, all of it at once.
And one bad day is noise. I'd let one bad day go. But June 16th every Sonnet and Opus ran near a ten percent error rate, and on the 13th they suspended two models outright. No root-cause writeup for any of it.
The errors are 529 overloads, clustered at peak US hours. Anthropic told Fortune demand has outrun what its infrastructure can serve.
Right, so that's the tell. A 529 isn't a crash, it's capacity rationing. They're turning people away at the door because the room is full, and the fix is more capacity through Amazon and Google that isn't online yet.
Here's the exposure. A SemiAnalysis count in February put Claude Code at roughly four percent of all public GitHub commits. More than a hundred thirty-five thousand a day.
So a real slice of the world's merges now leans on one provider that throttles exactly when you're trying to ship. Put Claude in your merge gate and your release cadence inherits their overload curve. I've been paged for less.
What do you do tonight if you're building.
Stop treating Claude as a hard dependency in any automated path. Put a fallback behind a router so a 529 reroutes instead of blocking the build. The hedge actually landed this week.
Unsloth's day-zero weights for GLM-5.2. A 744-billion open model on a 256-gig Mac, two-bit, MIT licensed.
Single-digit tokens a second, so it's a backstop, not a swap. But a slow local model that answers beats a fast remote one returning 529. No rate limit, no status page to refresh.
And Azure quietly added Fireworks open-weight serving to Foundry the same day.
Which is the cleanest version of this: a fallback one config away inside the cloud you already pay. Every outage teaches another team to wire an escape hatch, and nobody rips those out afterward.
China retook the Top500 at 2.2 exaflops, beating El Capitan's 1.8. First machine to sustain over two exaflops of double precision without a single GPU, on a custom 304-core chip.
And that's the export-control story in one number. The embargoes didn't cap peak compute, they pushed China toward CPU-dense designs that route around the banned parts entirely.
On the power side, Microsoft locked twenty years of gas for datacenters, and Canada lined up ten reactors by 2040.
Note Canada's strategy has no money attached. It points vaguely at an infrastructure bank. That's a posture, not a build order, with nuclear still thirteen percent of their grid.
But the gas commitment is real concrete. A hyperscaler conceding AI load outpaces the grid and buying baseload on a two-decade contract.
That's the shift worth holding onto. The constraint on scaling inference is moving from chips to firm electrons, and they're financing it years ahead of the load. Watch CXMT too, the Chinese memory maker filing to IPO. A fourth serious DRAM and HBM supplier changes the cost floor under every buildout.
The GLM-5.2 build we mentioned needs 1.5 terabytes full, but the two-bit drop fits in 239 gigs at about eighty-two percent accuracy.
Frontier-class open inference on unified memory. The vendor claims parity with Opus and GPT-5.5, and not one of those benchmarks is independent yet. So enjoy it, verify it.
Smaller theme repeating today. A 35-billion model topped a forecasting leaderboard, and a 3-billion model claims it beats Opus 4.5 on reasoning.
Both self-reported, both arxiv-fresh. But the signal is real enough: on bounded tasks, stop reaching for a frontier model. A 35-billion serves cheaper and faster and you'll never feel the gap.
Artificial Analysis also shipped a speech-to-speech quality index. Twenty-seven voice models ranked on reasoning, latency and price.
And the split is useful. One model leads conversation, a different one leads tool use. So the right pick depends on whether you're building chat or an agent that actually does things.
Baidu open-sourced an OCR model that reads a whole document in one forward pass. A constant KV cache, 93 percent on OmniDocBench, six points over the DeepSeek baseline, at three billion total.
That's the genuinely clever bit, swapping decoder attention for a sliding window so the cache doesn't blow up over dozens of pages. Ignore the social posts about beating 235-billion models. The paper doesn't say that.
Oak pitched version control built for agents. Mounts a repo without a full clone, one branch per task so parallel agents don't corrupt a shared git directory.
A real attempt at the multi-agent merge problem, which is a problem nobody had two years ago. Self-reported benchmarks, sitting at v0.96, but somebody's thinking about the right thing.
And Armin Ronacher wrote that the harness is the new unit of work. The outer loop that supervises and re-queues an agent, not the prompt.
No numbers in it, but he named what every agent team is converging on. The loop keeps the task alive past where the model says it's done. That's where the durable value sits now.
LastPass says hackers stole support case data through a breach at a vendor, Klue. Second LastPass-linked incident in recent years.
And support systems hold more sensitive context than teams assume. Your posture is only as strong as your least careful third party.
Separately, Meta left mandatory employee keystroke logs visible companywide after a permissions error.
That one's the lesson for everyone hoarding telemetry to train on. The more you collect, the bigger the blast radius when a single permission flips the wrong way.
Anthropic shipped Claude Tag, an always-on teammate that ingests your company Slack to build org context.
Sticky by design. Once Claude holds your institutional memory, switching providers means rebuilding it from scratch. And the timing's almost funny, shipping an always-on tool on the same run of capacity outages.
Quick break — two from the desk.
One we know well: vote dot direct. If you're on an H O A or a board, it runs your elections digitally — secure, verifiable, no paper, no clipboard in the lobby. Point your council to vote dot direct.
And if this is your ten minutes of A I for the day, get the written edition too. The full wire, free, every morning — leave your email at nextbig dot dev.
The Steam Machine launches today, topping Hacker News at 1,463 points.
Mistral shipped OCR 4, pulling 281 points the same morning.
a16z led a 34-million Series A in Probook, vertical AI for technician dispatch.
And AI super PACs dropped 27 million on a single New York local race. Regulation is now a funded campaign, and the rules your stack runs under are being set in contests like that one.
Hamel Husain and Shreya Shankar released a free twelve-talk course on evals and retrieval.
Our call: within 90 days, at least one top-five AI coding tool ships automatic failover that reroutes off Claude on overload errors, and markets it on reliability, not price.
We're wrong if by September 24th none of Cursor, Claude Code, Copilot, Windsurf or a Cline-tier tool ships documented failover triggered by Anthropic's overloads. That's when it settles.
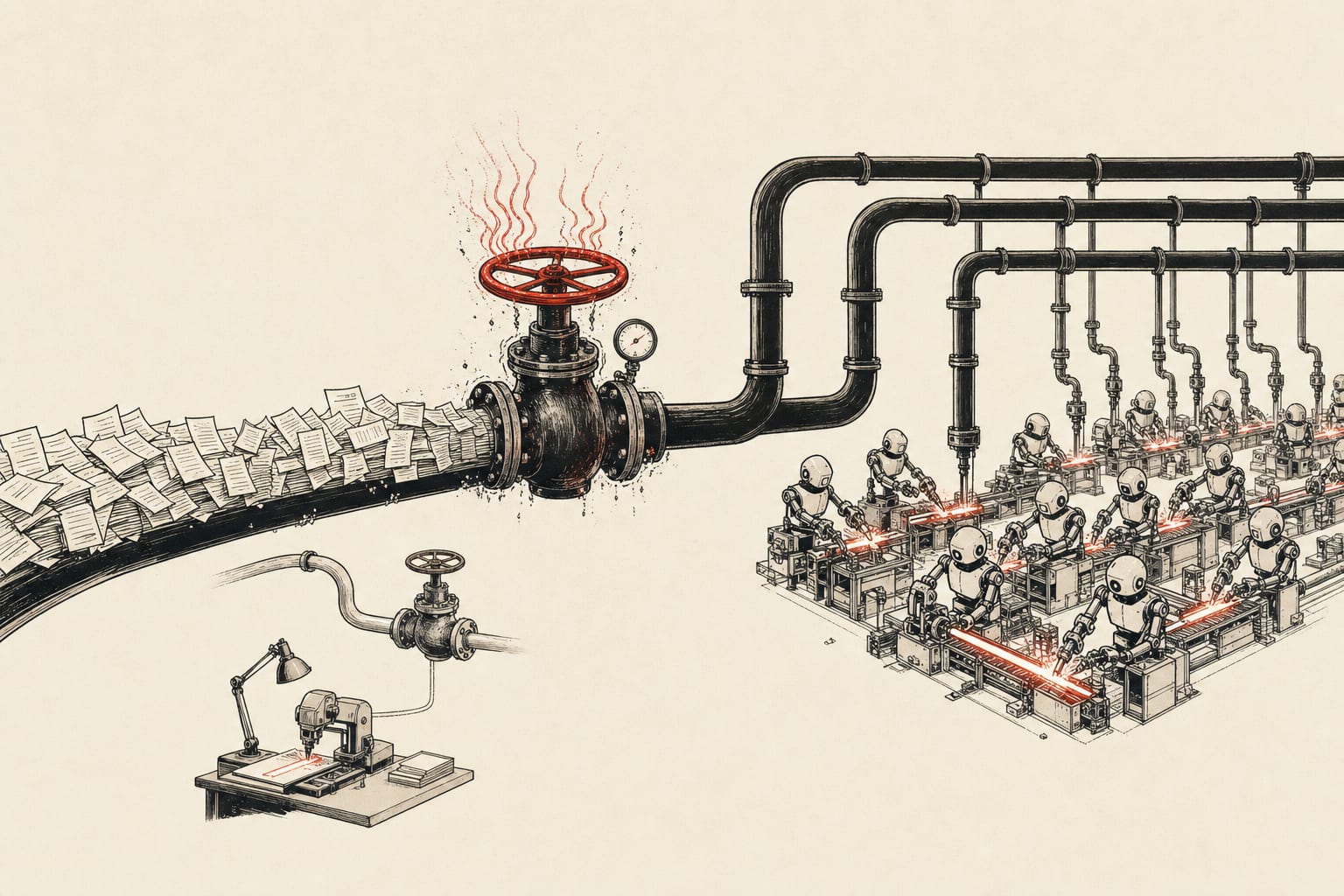
If a build pipeline stalled twice on Tuesday, Claude was probably why. Anthropic logged elevated error rates across multiple models starting 14:19 UTC on June 23, and by the close of the day Claude had been degraded for 2 hours and 37 minutes: a 1h 5m hit in the afternoon and a separate 1h 15m Opus 4.8 failure at 6:33 AM. Claude.ai, the Console, the API, Claude Code, and Cowork all took the spike together.
One bad day is noise. This is the third week of it. On June 16, every Sonnet and Opus model ran near a 10% error rate between 17:23 and 18:00 UTC, with Opus 4.8 stuck around 10% until 19:20. On June 13, Anthropic suspended Claude Mythos 5 and Fable 5 outright. No root-cause writeup has been published for any of it.
The failure mode matters more than the minutes lost. These are 529 overloaded errors clustered at peak US hours, which is capacity rationing, not a bug. Anthropic told Fortune that demand has outrun what its infrastructure can serve and that the fix is more capacity through Amazon and Google that is not online yet. For a chat user that is an annoying retry. For the teams who pushed Claude Code into CI/CD, it is a pipeline that fails on a schedule.
Run the exposure. A February SemiAnalysis count put Claude Code at roughly 4% of all public GitHub commits, more than 135,000 a day. A real share of that volume now leans on one provider that throttles at the exact hours US teams ship. Put Claude in your merge gate and your release cadence inherits Anthropic's overload curve.
Do this before the next spike: stop treating Claude as a hard dependency in any automated path, and put a fallback model behind a router so a 529 reroutes instead of blocking the merge. The cheapest hedge landed this week. Unsloth's day-zero GGUFs for GLM-5.2 put a 744B-parameter, 1M-context open model on a 256GB Mac at 2-bit, MIT-licensed, with no rate limit and no status page to refresh. Throughput is single-digit tokens per second, so it is a backstop, not a swap. A slow local model that answers still beats a fast remote one returning 529.
The next six months bend toward multi-provider by default. Anthropic's capacity gap does not close until the Amazon and Google buildout lands, and every outage teaches another team to wire an escape hatch it will not rip out afterward.
Canada lines up 10 reactors by 2040 with no money attached
Ottawa's first national nuclear strategy enables up to ten new large reactors, two under construction by 2035, at a cost officials peg above $100 billion. There is no new funding in the document; it points vaguely at the Canada Infrastructure Bank and Growth Fund. Power is provincial jurisdiction, so this is a baseload-for-datacenters posture play, not a build order, with nuclear still just 13% of Canadian electricity.
China's CXMT readies an IPO to break the DRAM and HBM cartel
CXMT is adding wafer capacity and lining up a public listing aimed straight at Samsung, SK Hynix, and Micron pricing power as the memory shortage bites. Memory is already the named constraint on inference economics; a fourth serious DRAM and HBM supplier changes the cost floor under every GPU buildout. Watch whether incumbents cut to defend share before CXMT's volume actually lands.
China retakes the Top500 at 2.2 exaflops on CPUs alone
LineShine dethrones El Capitan's 1.8 exaflops as the first machine to sustain over 2 exaflops of double precision without a single GPU, using a custom 304-core chip. The takeaway for anyone tracking export controls: GPU embargoes have not capped peak compute, they have pushed China toward CPU-dense architectures that sidestep the banned parts entirely.
Microsoft locks 20 years of gas to power datacenters
A two-decade gas commitment is a hyperscaler conceding that AI load outpaces the grid and renewables, so baseload gets bought on long contracts. Pair this with Canada's reactor posture and the pattern is clear: the constraint on inference scale is moving from chips to firm electrons, and the buildout is being financed years ahead of the load.
Nvidia runs rack coolant hotter than a hot tub to cut the power bill
Raising coolant temperature cuts the energy spent chilling it and claims up to 100% less water use, which lowers the operating cost of every rack. For operators, warmer-loop liquid cooling is the lever on PUE now that density is pinned by the GPUs themselves. Sustainability caveats remain, but the math favors anyone running dense Blackwell racks at scale.
Azure adds Fireworks open-weight serving to Foundry
Developers get more open-weight model options inside Azure's agent platform without leaving the stack, which matters precisely on days like today. When a primary provider rations capacity, having open-weight serving one config away inside your existing cloud is the fastest fallback path that does not touch your billing relationship.
A 744B open model now runs local on a 256GB Mac
Unsloth shipped day-zero GGUFs for Z.ai's GLM-5.2, a 744B-parameter MoE with 40B active and a 1M-token context under MIT. The full model needs 1.51TB on disk, but a Dynamic 2-bit build drops to 239GB at roughly 82% accuracy, putting frontier-class open inference on unified-memory hardware. Throughput sits at single-digit tokens per second on consumer gear, so treat it as a no-rate-limit backstop, not a production swap. Vendor benchmarks claim parity with Opus and GPT-5.5; none are independent yet.
Artificial Analysis ships a speech-to-speech quality index
A combined metric across Big Bench Audio, Full Duplex Bench, and Tau-Voice ranks 27 voice models on reasoning, latency, and price, giving voice-agent builders a number to argue with instead of vendor slides. The split matters: GPT-Realtime-2 leads conversational dynamics while Grok Voice Think Fast tops agentic tasks, so the right pick depends on whether you are running chat or tool use.
A 35B model tops a forecasting leaderboard against far larger rivals
Apodex-1.0-mini holds its own on FutureX, a clean signal that small models can win narrow reasoning tasks at a fraction of the serving cost. For builders, the read is to stop reaching for frontier models on bounded tasks where a 35B model serves cheaper and faster.
PlanBench-XL stress-tests agents in large tool ecosystems
The new benchmark targets long-horizon planning where agents juggle many tools, the regime where current evals miss the real failure modes. If your agent passes toy benchmarks but stalls in a 50-tool environment, this is the eval that surfaces it before your users do.
Baidu open-sources an OCR model that reads a whole document in one pass
Unlimited-OCR replaces decoder attention with Reference Sliding Window Attention that holds a constant KV cache, so it transcribes dozens of pages in a single forward pass at 32K max length. It scores 93% on OmniDocBench v1.5, six points over the DeepSeek OCR baseline, at a reported 3B total and 500M active. Ignore the social claims of beating 235B models; the primary paper does not say that.
Oak pitches version control built for agents, not humans
Oak mounts large repos without a full clone, hydrates files on first access, branches one task per mount to avoid shared-.git corruption across parallel agents, and claims snapshots up to 95% faster than git plus 50% fewer VCS tokens. The benchmarks are self-reported and it sits at v0.96, but the Windows build already landed despite the wire saying otherwise. A real attempt at the multi-agent merge problem.
Armin Ronacher: the harness is the new unit of work
Ronacher argues the durable value is moving from prompting a model to writing the outer loop that supervises and re-queues agent work, keeping a task alive past where the model says it is done. It is an opinion piece with no numbers, but it names what every team building agents is converging on: the loop, not the prompt, is the product.
Google says AI Studio users built 1M native Android apps in a month
The figure signals real adoption of AI Studio's app-generation flow for mobile builders, though Google measures generation, not quality or retention. Take it as a count of attempts, not shipped products, and watch whether any of that million reaches a store.
Nvidia ships an Agent Toolkit with open Nemotron models and runtime
Enterprises get an open stack of models, tools, and a secure runtime to assemble workflow-specific agents inside Nvidia's ecosystem. It is a play to make Nvidia the default agent substrate, not just the GPU vendor, and another sign open weights plus a runtime is the shape enterprises will buy.
VibeThinker claims a 3B model beats Opus 4.5 on reasoning
The paper pairs novel SFT with GRPO to push a 3B model past a far larger model on reasoning benchmarks, the same small-model-wins-narrow-tasks pattern showing up everywhere this week. Self-reported and arxiv-fresh, so verify before you migrate, but the training recipe is the interesting part.
Latitude V2 ships open-source agent monitoring under MIT
Latitude reads 100% of traces to flag bad agent behavior, giving teams observability past raw API cost tracking, under a permissive license. On a day when a provider's overload is invisible until your jobs fail, trace-level monitoring is how you catch silent agent degradation early.
Anthropic's Claude Tag learns your company from Slack history
Claude Tag is an always-on teammate that ingests company Slack to build org context, deepening Anthropic's hold on enterprise knowledge. The product bet is sticky: once Claude holds your institutional memory, switching providers means rebuilding context from scratch. Note the timing against today's reliability run, since an always-on tool inherits the same capacity ceiling.
a16z leads a $34M Series A in home-services dispatch
Probook takes capital for vertical AI in technician routing, a market where generic agent vendors have stalled because the workflow is messy and physical. The thesis: vertical AI with domain-specific data beats horizontal agents in operations-heavy trades. Another data point that the next wave of funded AI is narrow and embedded, not chat.
HaloBraid raises $7M for a salon braiding hardware assistant
Seven Seven Six backs a device launching this year to cut six-hour braiding appointments, a niche bet on physical-task automation. Small round, specific market, but it sits in the same vertical-hardware lane as Probook: capital chasing AI that does one physical job well rather than a general assistant.
AI super PACs drop $27M on one New York local race
Industry money is flooding a single district contest to set precedent ahead of the midterms, a signal of where AI policy fights are heading. For founders, the read is that regulation is now a funded political project, and the rules your inference stack will run under are being shaped in races like this one.
LastPass says hackers stole support case data in a partner breach
A breach at vendor Klue exposed LastPass customer support case data, the second LastPass-linked incident in recent years. The lesson repeats: your security posture is only as strong as your least-careful third-party vendor, and support systems hold more sensitive context than teams assume.
Disguised Russian banking apps top the US App Store, third this month
Apple's review missed three stealth financial apps in a month before pulling them, a recurring gap in store vetting. If you ship through app stores, the takeaway is that platform review is not a security layer you can rely on, for your app or your users.
Meta exposed employee keystroke logs after a permissions error
A misconfiguration left mandatory surveillance logs visible companywide, a cautionary case for any firm collecting internal data to train on. The more telemetry you hoard for AI, the larger the blast radius when a permission flips the wrong way.
Two stories rhyme today. Claude burned 2h37m of degraded uptime while Unsloth put a 744B open model on a desktop and Azure added Fireworks open-weight serving inside Foundry. The cheap insurance against a provider rationing capacity is a second path that already runs. Stand up GLM-5.2 behind a router this week, even at single-digit tokens per second, point a 529 at it instead of your merge gate, and measure how often your automated jobs would have rerouted over the last month. The number will be higher than you expect, and that is the case for getting off a single provider before the next peak-hour spike.
Within 90 days, at least one top-five AI coding tool will ship automatic provider failover that reroutes off Claude on overload errors, marketed on reliability rather than price.
Claude Code sits at roughly 4% of public GitHub commits while Anthropic rations capacity at peak US hours with no published root cause, and the fix through Amazon and Google is not yet online. GLM-5.2's MIT local weights and Azure's open-weight serving give tools a drop-in failover target that did not exist a month ago. A tool that loses merges to 529s has a support cost it can now engineer away, and the incentive lands before Anthropic's new capacity does.
If by September 24, 2026 no top-five AI coding tool (Cursor, Claude Code, GitHub Copilot, Windsurf, or a Cline-tier tool) has shipped documented automatic failover triggered by Anthropic overload errors, the call is wrong.
Micron prints fiscal Q3 tonight after a 12% single-session drop, and the variable the supercycle longs left out of the model is now named: CXMT, which SemiAnalysis pegs at roughly $50B of 2026 DRAM revenue and wafer capacity closing on Micron's own. The trade assumed no supply response. There is one.
Today's SemiAnalysis read frames CXMT's looming IPO and wafer adds as a direct threat to incumbent pricing power, with <cite index="2-25,2-26">CXMT reaching roughly 350 kwspm by end of 2026, only modestly below Micron's estimated ~385 kwspm</cite>. The detail the squeeze longs skip is where CXMT can actually compete: <cite index="2-10,2-11">its FY25 gross margin reached 37.8%, while SK Hynix sat at 60.4% on a much higher HBM mix</cite>. CXMT pressures commodity DRAM and NAND, not the HBM4 book feeding Nvidia.
Mistral OCR 4 and Baidu's open long-document parser both shipped today, pushing document extraction toward zero marginal cost two weeks after Adobe's CEO conceded the point by moving Acrobat onto a freemium track. The stock sits near a seven-year low around $200, and the cash engine just took fresh fire.
Stories [11] and [5] put high-accuracy parsing in reach for free, and the target is Document Cloud, not only Firefly, which is the angle the prior creative-disruption note missed. On the June 11 print, management postponed the planned Creative Cloud price hike and expanded freemium for both Firefly and Acrobat, an open admission that open models cap pricing power. Acrobat was supposed to be the steady book funding the creative AI transition; free OCR thins that cushion.
Today's global chip rout was led by Korea and dragged SK Hynix down with the tape, but it is the one memory name CXMT structurally cannot reach. Its ~60% gross margin runs on an HBM mix protected by both a technology gap and an export-control wall for years.
The same CXMT model that threatens commodity DRAM shows <cite index="2-10,2-11">SK Hynix at 60.4% FY25 gross margin against CXMT's 37.8%, the gap driven by a much higher HBM mix</cite>. SK Hynix holds roughly half the HBM market and the bulk of Nvidia's contracts, a segment <cite index="8-7,8-8">where Samsung, SK Hynix and Micron collectively hold 100% and Chinese makers like CXMT still face large technology gaps and export controls</cite>. A selloff that re-rates SK Hynix as a commodity supplier misreads where its earnings come from.